DreamMaker: Making High-quality Text-to-3D Generation with 3D Consistent Regularization
DreamMaker generates high-quality and high-resolution 3D models from given text prompts.
Interactable Meshes
an asian Santa Claus
a metal bunny sitting on top of a stack of chocolate cookie
an astronaut on a horse
a DSLR photo of a pug made out of metal
a DSLR photo of a tiger dressed as a doctor
a human skull with a vine growing through one of the eye sockets
Beautifully designed hyper-realistic futuristic electric vehicle for elderly people, highest poly count, highest contrast, highest detail, highest quality, UHD
Beautifully designed hyper-realistic psychedelic bee-concept futuristic fighter jet aircraft, highest contrast, highest poly count, highest detail, highest quality, UHD
An octopus and a giraffe having cheesecake
Abstract
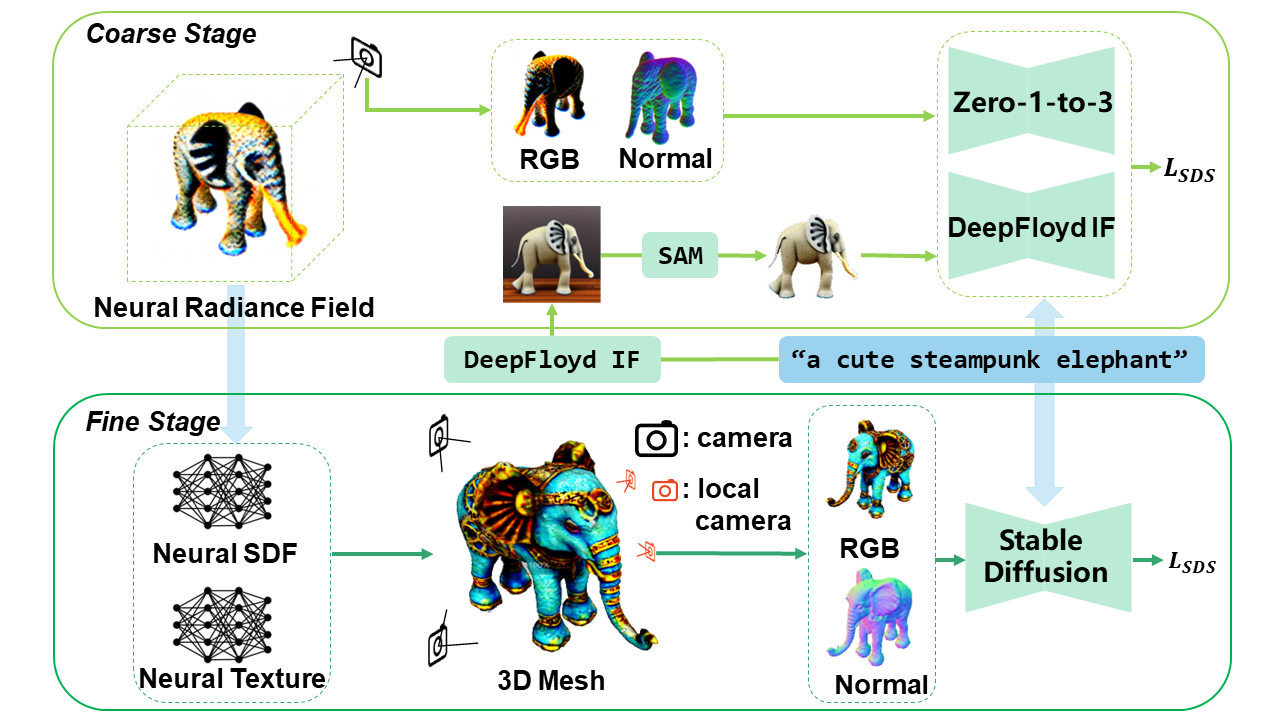
2D diffusion-based text-to-3D generation models often encounter the Multi-face Janus problem, which arises due to the absence of 3D consistency in multi-view image generation. To address this challenge, we propose a novel text-to-3D generation framework called DreamMaker. Our approach incorporates 3D geometry consistent regularizations to enhance multi-view consistency and improve the overall quality of 3D generation. The DreamMaker pipeline incorporates a multi-view image generation model and a large text-to-image model, ensuring both 3D consistent and semantically accurate generation. Additionally, we introduce a refinement module that leverages improved 3D scene parameterization and an adaptive camera view sampling strategy to extract high-resolution meshes and textures. Experimental evaluations demonstrate that DreamMaker achieves impressive results. Importantly, it significantly mitigates the occurrence of the Janus problem by approximately 60%. Comparative studies also indicate that DreamMaker outperforms state-of-the-art approaches such as DreamFusion, Magic3D, and SJC, as it garners more user preferences.
Comparison with state-of-the-art models
Although Magic3D and ProlificDreamer are able to generate high-quality objects in some cases, multi-view inconsistency still occurs in many other cases. For example, in Magic3D, wheels of the vehicle in the first case have inconsistent directions and airplane in the second case has multi-heads. Our DreamMaker further introduces 3D consistency to avoid the Janus problem and can still produce high-resolution meshes and high-quality textures. We use the threestudio implementation for all the baselines.
Magic3D-IF-SD ProlificDreamer Ours
Beautifully designed hyper-realistic futuristic electric vehicle for elderly people highest poly count highest contrast highest detail highest quality UHD
Beautifully designed hyper-realistic psychedelic bee-concept futuristic fighter jet aircraft highest contrast highest poly count highest detail highest quality UHD
an Asian Santa Claus
a metal bunny sitting on top of a stack of chocolate cookie
More ablation studies
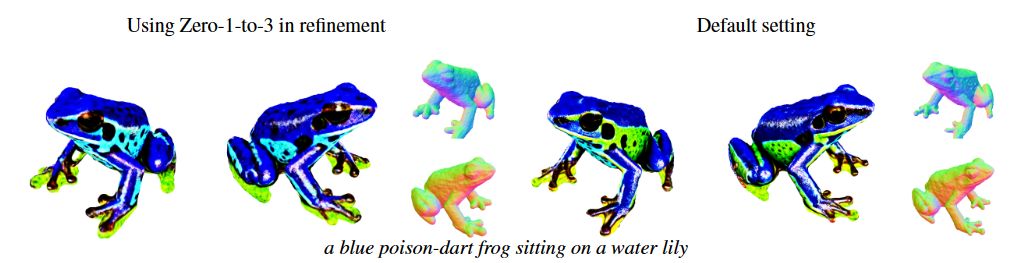
we present a series of additional ablation studies that extend beyond the scope of the main manuscript. These investigations delve into various facets of our model's performance and behavior, including: (1) the role of CLIP regularization in texture and shape refinement; (2) the benefits of the warm-up phase in the coarse stage;(3) the capabilities in generating human-centric 3D models; (4)the impact of using different initial images and random seeds for initialization; (5) the analysis of the effects with and with- out Alpha Entropy Regulation, and Smoothness; (6) the effects of utilizing Zero-1-to-3 during the refinement stage.
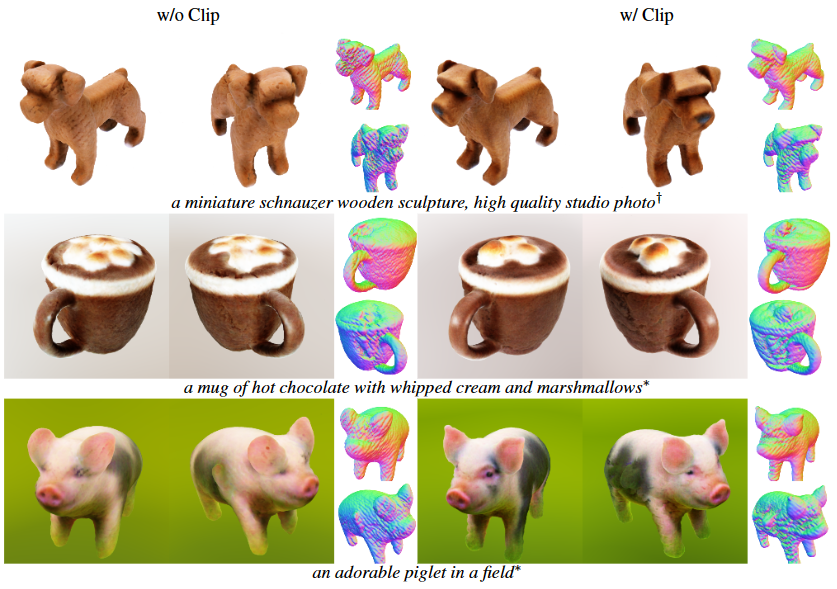
CLIP Regulation
During the coarse stage of our model, an additional CLIP loss is integrated to refine the generative process, significantly enhancing shapes and textures. The figure below exemplifies this improvement: the surfaces of the miniature schnauzer and piglet display considerably sharper textures subsequent to the application of the CLIP loss. Notably, the facial features of the piglet, such as the eyes and nose, achieve enhanced realism in the final row. This can be attributed to the CLIP regulation's role in optimizing the generated scenes to align closely with the textual prompts via CLIP similarity metrics.
Zero-1-to-3 warmup in the coarse stage
In the beginning of the coarse stage, we implement the Zero-1-to-3 warmup with the guidance of RGB. During this phase, in the absence of DeepFloyd IF, the 3D object is able to achieve a stable, rough initialization, characterized by consistent geometric integrity. This foundational procedure benefits to reinforcing both the texture fidelity and geometric stability in the final 3D model outcomes. Notably, post-warmup, the geometric configurations of objects, such as ice-cream sundaes and saguaro cactus, exhibit markedly improved realism. The implementation of the Zero-1-to-3 warmup lays the groundwork for a robust and realistic geometric framework in the nascent stages of model training.

Human-centric 3D Asset Generation
Our architecture demonstrates proficiency in the creation of human-related assets. By processing prompts that are specifically crafted for human figures, our architecture can generate 3D representations of human faces and bodies with high fidelity and consistency from multiple viewpoints. Remarkably, this is achieved without any predefined knowledge of human anatomical structures. For instance, our model successfully generates a realistic bust of an Asian Santa Claus. Additionally, our generated astronaut, Deadpool and Spiderman display a 3D geometric consistency that adheres closely to human anatomical form.

Random Initialization
We assess the impact of using different seeds and initialization images. Our findings indicate that our method is not notably affected by the choice of random initialization. In contrast, DreamFusion and Magic3D heavily relies on the selection of random seeds in achieving high-quality results and avoiding the multi-face Janus problem.

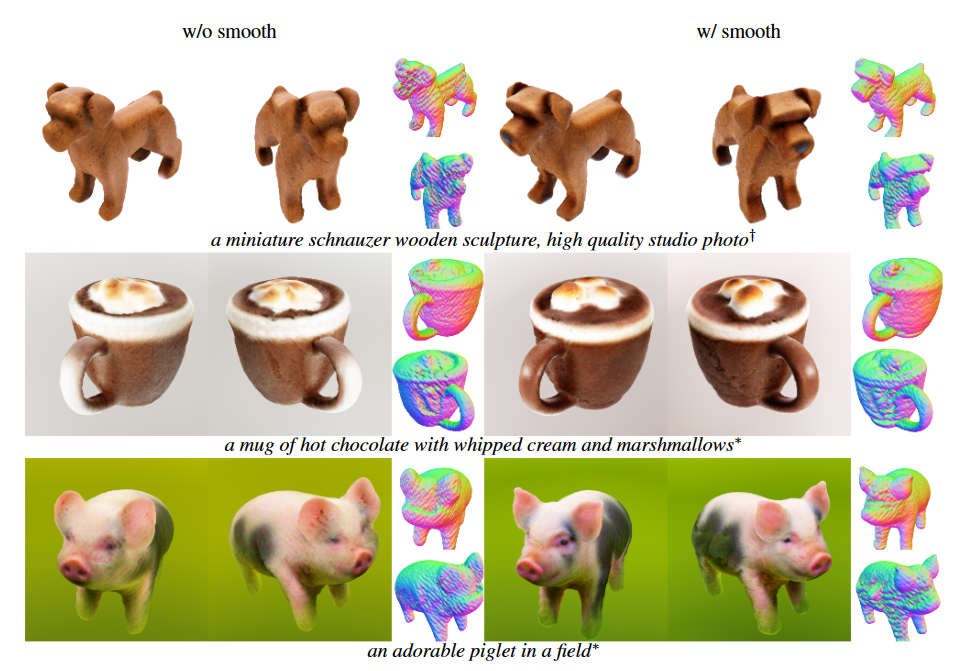
Smooth Regulation
We conduct an evaluation of the impact of the smoothness loss on our coarse-stage results. Our findings suggest that applying smoothness regulation can enhance the quality of textures. Simultaneously, it has a modest beneficial effect on the quality of the mesh, as visualized via the surface normal maps.